Data Sources
A Data Source allows you to define where and how you are pulling data from a communication channel.
Overview
A Data Source stores the configuration necessary to retrieve data from a communication channel, process that data, and ingest it into Relativity Trace.
Data Sources List
This list covers currently available Data Sources.
Generic Data Sources
If your specific data source is not found on this page, Trace has numerious capabilities to support your data using the below methods.
| Type | Data Source | Notes | Data Transfer Method |
|---|---|---|---|
| Generic | EML Drop | For deliverying daily EML exports from various systems | Trace Shipper OR R1 SFTP |
| Generic | RSMF Drop | For deliverying chat-like data (social, mobile, etc…) | Trace Shipper OR R1 SFTP |
| Generic | Mailbox with 3rd party data | For deliverying data from mobile (and other) providers such as TeleMessage who deliver their data to customer mailbox | Email Data Sources |
| Generic | Zip Drop | For already processed structured data | Trace Shipper OR R1 SFTP |
| Generic | Generic Audio Data | For audio data | Trace Shipper OR R1 SFTP |
| Generic | Monitored Individuals from any source using Trace ZipDrop | For custom HR / People data | Trace Shipper OR R1 SFTP |
Email Data Sources
| Type | Data Source | Data Collection Method | Data Transfer Method |
|---|---|---|---|
| Microsoft O365 Email and Calendar | Cloud-to-cloud | Relativity Cloud Collect | |
| Microsoft O365 Mail Archive Mailbox | Cloud-to-cloud | Relativity Cloud Collect | |
| Google Mail | Cloud-to-cloud | Relativity Cloud Collect | |
| Bloomberg Mail | Cloud-to-cloud OR R1 SFTP Drop | Relativity Cloud Collect | |
| Microsoft Exchange Server | On-premises software required - Relativity Collect On-Premises | Trace Shipper |
Chat Data Sources
| Type | Data Source | Data Collection Method | Data Transfer Method |
|---|---|---|---|
| Chat | Bloomberg Chat and PChat | Cloud-to-cloud OR R1 SFTP Drop | Relativity Cloud Collect |
| Chat | ICE Chat | Cloud-to-cloud (via Relativity Collect) | Relativity Cloud Collect |
| Chat | Refinitiv Eikon Chat | Cloud-to-cloud (via Relativity Collect) | Relativity Cloud Collect |
| Chat | Symphony | On-premises software required - Merge1 | Trace Shipper |
| Chat | Skype for Business | On-premises software required - Merge1 | Trace Shipper |
| Chat | Microsoft O365 Teams Chat | Cloud-to-cloud | Relativity Cloud Collect |
| Chat | FXConnect | On-premises software required - Merge1 | Trace Shipper |
| Chat | Cisco WebEx Teams Chat | On-premises software required - Merge1 | Trace Shipper |
| Chat | ServiceNow | On-premises software required - Merge1 | Trace Shipper |
| Chat | Google Chat | Cloud-to-cloud | Relativity Cloud Collect |
| Chat | Salesforce Chatter | On-premises software required - Merge1 | Trace Shipper |
| Chat | Slack Enterprise Chat | Cloud-to-cloud | Relativity Cloud Collect |
| Chat | Microsoft Yammer | On-premises software required - Merge1 | Trace Shipper |
| Chat | Facebook Workplace | On-premises software required - Merge1 | Trace Shipper |
| Chat | YieldBroker | On-premises software required - Merge1 | Trace Shipper |
Voice Data Sources
| Type | Data Source | Data Collection Method | Data Transfer Method |
|---|---|---|---|
| Voice | Zoom Audio | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Symphony Audio | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | WebEx Teams Audio | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Vodafone | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Avaya | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Cloud 9 | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Verba/Verint | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Mitel | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Liquid Voice | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | O2 | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Microsoft Teams Audio | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
| Voice | Skype for Business Audio | On-premises software required - Intelligent Voice | Trace Shipper OR R1 SFTP |
Mobile Data Sources
Trace supports picking up mobile data from customer’s mailbox. In other words, mobile data is delivered to customer’s mailbox and then picked up by Trace from the mailbox.
| Type | Data Source | Capture Methods | Data Collection Method | Data Transfer Method | Notes | License |
|---|---|---|---|---|---|---|
| Mobile | via Native WhatsApp; via MS Teams; via Slak; via Leap Work (iOS and Android) | LeapXpert delivers to customer mailbox | Email Data Sources | Additional license with LeapXpert is required | ||
| Mobile | via MS Teams; via Leap Work (iOS and Android) | LeapXpert delivers to customer mailbox | Email Data Sources | Additional license with LeapXpert is required | ||
| Mobile | WeChat miniapp | via Leap Work (iOS and Android) | LeapXpert delivers to customer mailbox | Email Data Sources | Additional license with LeapXpert is required | |
| Mobile | SMS/MMS | via native SMS/MMS app on the phone; via MS Teams; via Leap Work (iOS and Android) | LeapXpert delivers to customer mailbox | Email Data Sources | Additional license with LeapXpert is required | |
| Mobile | iMessage | via native iMessage app on iphone | LeapXpert delivers to customer mailbox | Email Data Sources | iMessage capture requires user Apple ID and synchronizing the data from iCloud | Additional license with LeapXpert is required |
| Mobile | Telegram | via native Telegram app | LeapXpert delivers to customer mailbox | Email Data Sources | Additional license with LeapXpert is required | |
| Mobile | Signal | via Leap Work (iOS and Android) | LeapXpert delivers to customer mailbox | Email Data Sources | Additional license with LeapXpert is required | |
| Mobile | WeCom | via native WeCom app | LeapXpert delivers to customer mailbox | Email Data Sources | Additional license with LeapXpert is required | |
| Mobile | LINE | via Leap Work (iOS and Android) | LeapXpert delivers to customer mailbox | Email Data Sources | Additional license with LeapXpert is required |
Collaboration Data Sources
| Type | Data Source | Data Collection Method | Data Transfer Method |
|---|---|---|---|
| Collaboration | OneDrive for Business | On-premises software required - Merge1 | Trace Shipper |
| Collaboration | SharePoint | On-premises software required - Merge1 | Trace Shipper |
| Collaboration | Google Drive | Cloud-to-cloud | Relativity Cloud Collect |
| Collaboration | Box | On-premises software required - Merge1 | Trace Shipper |
| Collaboration | AWS S3 | On-premises software required - Merge1 | Trace Shipper |
| Collaboration | Dropbox | On-premises software required - Merge1 | Trace Shipper |
Archive Data Sources
| Type | Data Source | Notes | Data Collection Method | Data Transfer Method |
|---|---|---|---|---|
| Archive | Proofpoint | On-premises software required - Relativity Collect On-Premises | Trace Shipper | |
| Archive | Enterprise Vault | On-premises software required - Relativity Collect On-Premises | Trace Shipper | |
| Archive | Smarsh | Data must be recieved via Scheduled Export configured in Smarsh | N / A | R1 SFTP |
People / HR Data Sources
In Trace People / HR data is refered to as Monitored Individuals. A Monitored Individual is a person within the organization whose communications are being analyzed for misconduct.
Monitored Individuals are used as a unit of billing by Relativity Trace. Generally a Relativity Trace license will specify a number of Monitored Individuals available and the number of data sources they can be used on.
| Type | Data Source | Data Collection Method | Data Transfer Method |
|---|---|---|---|
| Monitored Individual | Microsoft Azure Active Directory | Cloud-to-cloud | Relativity Cloud Collect |
| Monitored Individual | Microsoft Active Directory | On-premises software required - Relativity Collect On-Premises | Trace Shipper OR R1 SFTP |
Data Source Details
Sections of a Data Source
-
General: this tab houses general identifying information and status for the data source. These fields are described in further detail below.
- Data Source Type: Type of the data source
- Name: The name of the Data Source
- Document Type Name: A non-required name that will propagate to the Trace Type field on the documents that come in through this Data Source
- If this field is left empty, the name of the Data Source will be used instead
- Provider Type: The type fo communications that are being collected (Audio, Written, etc.)
- Alternative Monitored Individual Identifier Field: Field which can be used to have different Monitored Individual identifier used when retrieving data from different data sources
- Ingestion Profile: Ingestion Profile used to load data from this Data Source
- Start Date: Date from which data will be pulled/pushed into Relativity
-
End Date: Optional date to which data will be pulled/pushed into Relativity.
- If both dates are present, data between Start Date and End Date will be collected. If Ingestion State is later than Start Date, then only data between Ingestion State and End Date will be collected.
- If Start Date is present but End Date is empty, data between Start Date and Now will be collected. If Ingestion State is later than Start Date, then only data between Ingestion State and Now will be collected.
- If Start Date is empty but End Date is present, data between Ingestion State and End Date will be collected.
- If neither Start Date nor End Date is present, data between Ingestion State and Now will be collected.
- See Data Retrieval for more details.
- Last Runtime (UTC): The timestamp when this Data Source was last executed
- Enabled Time: The timestamp when this Data Source was last enabled
- Disabled Reason: An explanation for why a data source was automatically disabled by the system
- Status: The last status message recorded by the Data Source
- Last Error Date: Timestamp of the last time this Data Source failed, if it happened recently (based on Last Error Retention in Hours setting under Data Source Specific Fields)
- Last Error: Error message from the last time this Data Source failed, if it happened recently (based on Last Error Retention in Hours setting under Data Source Specific Fields)
-
Settings: Configures standard settings required for the specific Data Source Type. These settings can be found on specific data source documentation pages.
-
Trace Monitored Individuals: Configures which monitored individual’s data should be retrieved from the data source. See Monitored Individuals for more information.
-
Data Transformations: Determines which data transformations to apply to documents prior to ingestion into Relativity by this data source. See Data Transformations for more information.
-
Data Batches: The data batches which have been generated by this data source. See Data Batches for more information.
-
Advanced Configuration: Different data source types have different configuration options. This section updates dynamically to allow access to these configuration options. See Advanced Configuration and the documentation of your specific Data Source Type for more information.
-
Console
- Enable/Disable Data Source: Enables (or disables) data retrieval for a particular data source.
-
Reset Data Source: Disables and resets data source to retrieve data from the specified Start Date.
Depending on Import settings, enabling a reset Data Source could duplicate data in the Workspace.
-
Advanced Configuration
This section contains additional settings which are not associated with specific Relativity Fields. The settings described here are common across all Data Source Types. Type-specific settings are documented under their respected Data Source sections.
- Aip Application Id: This parameter is deprecated. Leave it empty.
- Aip Tenant Id: This parameter is deprecated. Leave it empty.
- Frequency In Minutes: Number of minutes worth of data to pull for each attempted data pull via Data Retrieval Task.
- Merge Batches During Cold Start: When set to True it will merge initial Data Batches into ont, big Data Batch.
- Max Number Of Batches To Merge: Input Value to control number of hours collected per Data Batch created, dependent on Frequency in Minutes value. This parametr is used when Merge Batches During Cold Start is set to True.
See Data Retrieval for more details about Frequency In Minutes, Merge Batches During Cold Start and Max Number Of Batches To Merge.
- Collect Job Timeout In Minutes: 1440 (default) – Time interval after which a Data Batch will be automatically moved from Retrieving to Abandoned state.
- Collection Period Offset In Minutes: 0 (default) – Modify Collection Period by adding offset in minutes to both Start and End Date. This parameter is used to collect data that are available to be retrieved with some delay e.g. 24 hours.
- Only Retrieve Natives And Copy To Folder: Relative path to the fileshare folder (e.g. BloombergMailDrop\Drop). This parameter is used to improve performance of ingesting big portion of data e.g. 300,000 files (typical scenario for Bloombertg Chat and Mail). When the parameter is set, the Data Source will only retrieve files and store those files in the given folder. Neither enrichmnet nor ingestion will be performed on those files. To complete enrichment and ingestion, another Data Source (Globanet type of Data Source) needs to be created and configured to point to the folder. Eventually, there will be two Data Sources:
- Retrieving - For retrieving files via Collect.
- Processing - for enriching and ingestion those files in smaller chunks (1000 files each).
-
Password Bank Used to specify known passwords to attempt while encountering protected native files. Multiple passwords can be separated by the pipe character,
|. Passwords containing the pipe character are supported through escaping the pipe character with a second pipe. Pipes are always escaped left to right.Example Password Bank:
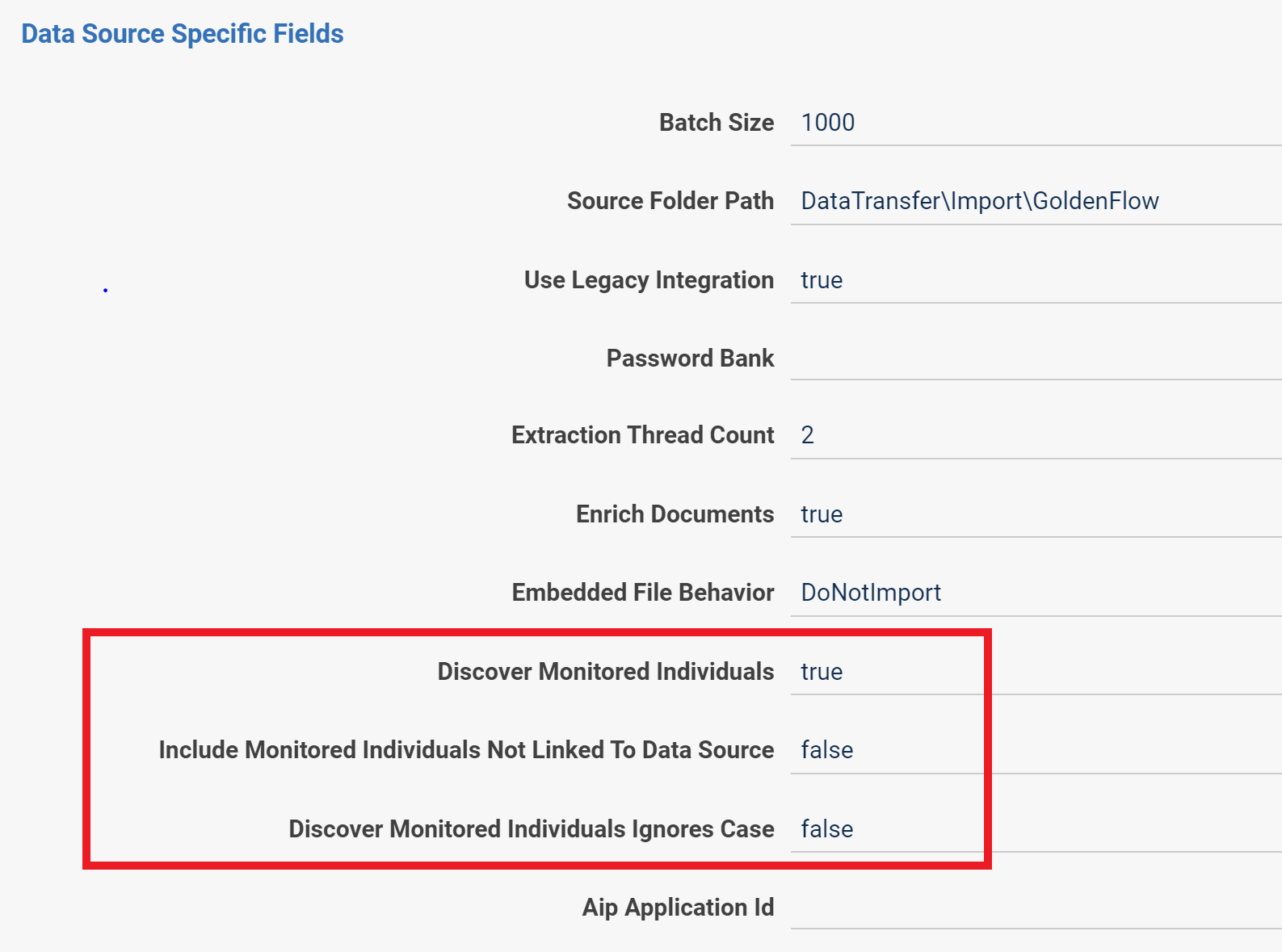
passw0rd|Trace1234!|aaa|bb|cccc||dd||eee|||ff|||ggg||||hhh|||||Yields the following passwords: -passw0rd-Trace1234!-aaa-bb-cccc|dd|eee|-ff|-ggg||hhh|| - Extraction Thread Count: The number of documents to extract in parallel.
- Enrich Documents: Whether or not to extract metadata and children from original documents. Valid values:
trueorfalse - Embedded File Behavior: Embedded files are defined as attachments without file names. Most commonly these are in-line images. This setting changes the import behavior for embedded files. Valid options are:
Import- Import all embedded files (top level and child) as separate documents in Relativity Trace.DoNotImportFromAttachments- Import embedded files from top level documents only. Do not extract embedded files from child documents.-
DoNotImport- Do not import any embedded files.Both the
ImportandDoNotImportFromAttachmentssettings will greatly increase document volumes in Relativity Trace.
- Discover Monitored Individuals: See Discovery of Monitored Individuals
- Include Monitored Individuals Not Linked to Data Source: See Discovery of Monitored Individuals
- Discover Monitored Individuals Ignores Case: See Discovery of Monitored Individuals
- Last Error Retention In Hours: The length of time to persist any message in the
Last Errorfield. -
Health Check Failure Window Length in Minutes: See [Data Source Auto-Disable] (#data-source-auto-disable)
-
Ingestion State: Timestamp of last Data Source execution.
This parameter is only visible on **Data Source Layout (dev)** Layout. {: .info} - Retry Policy: Data Batch Automatic Custom Retry Policy. Defined as intervals in minutes between each Data Batch retry. It overwrites Instance Settings Retry Policy. If empty - Instance Settings Retry Policy will be used. Example values:
[720,720,360,180,180]or[]
Data Source Auto-Disable
Trace will automatically disable data sources that are identified as unhealthy or have critical configuration errors that will require intervention by the user. Trace will automatically disable a data source for the following reasons:
- Data source has not had any successful data batches in the number of minutes configured on the
Health Check Failure Window Length in Minutesfield (if not set, default is 24 hours) - Globanet data source is enabled without enabling Globanet (Merge1) at the workspace level
Auto-disabled data sources will have their Disabled Reason field populated to show that it was disabled by the system. The data source will also have error details outlining the failures that caused the system to disable it.
Discovery of Monitored Individuals
Some Data Sources combine data from several places into a single import flow. In that scenario, it may not be clear which Monitored Individual is the source of a given document and no Monitored Individual will be tagged. To address this issue, Trace has introduced the Discover Monitored Individuals option on every Data Source. If enabled, Trace will look inside of the document and tag Monitored Individuals defined on the Data Source if they are found in headers inside the document. Monitored Individuals are recognized by identifier and all secondary identifiers.
There is also the option to discover Monitored Individuals that are not linked to the Data Source with the setting Include Monitored Individuals Not Linked To Data Source. If Discover Monitored Individuals is false, this setting will take no action. If Discover Monitored Individuals is true and Include Monitored Individuals Not Linked To Data Source is false, this setting will take no action and it will only discover Monitored Individuals that are linked to that Data Source. If Discover Monitored Individuals is true and Include Monitored Individuals Not Linked To Data Source is true, it will use all of the Monitored Individuals in the workspace to tag documents.
By default, Monitored Individual discovery ignores case in the domain portion of the email address but not the name portion. For example, John.DOE@URL.COM will match John.DOE@url.com, but not john.doe@url.com.
To ignore case in the entire email address during Monitored Individual discovery, use the Discover Monitored Individuals Ignores Case setting. For example, John.DOE@URL.COM will match always John.DOE@url.com, but only match john.doe@url.com if Discover Monitored Individuals Ignores Case is set to true.
Monitored Individual Discovery On Merge1 Data Sources
Merge1’s EWS Data Source only looks for Monitored Individuals in the X-UserMailbox header of an email. This header is provided by Merge1 and typically contains exactly one Monitored Individual.
Monitored Individual Discovery On Other Data Sources
All other data sources discover Monitored Individuals based on the FROM, TO, CC, and BCC headers. Any Monitored Individual on the Data Source with an identifier (primary or secondary) contained in any of these headers will be associated with the document.
Supported File Formats
Discovery of monitored individuals is based on finding the email addresses of monitored individuals in the headers of an email file. Therefore, it will only work properly on .eml, .msg, and .rsmf (Relativity Short Message Format) files. Any other file format is not currently supported.
Usage of Alternative Monitored Individual Identifier Field
Alternative Monitored Individual Identifier field give possibility to choose Fixed-Length Text field from Monitored Individual which we indicate to be main identifier to retrieve data from source. After retrieve, Monitored Individuals are always link to proper Identifier field.