Data Batches
Data batch is a unit of ingestion work for Relativity Trace.
Data Batches
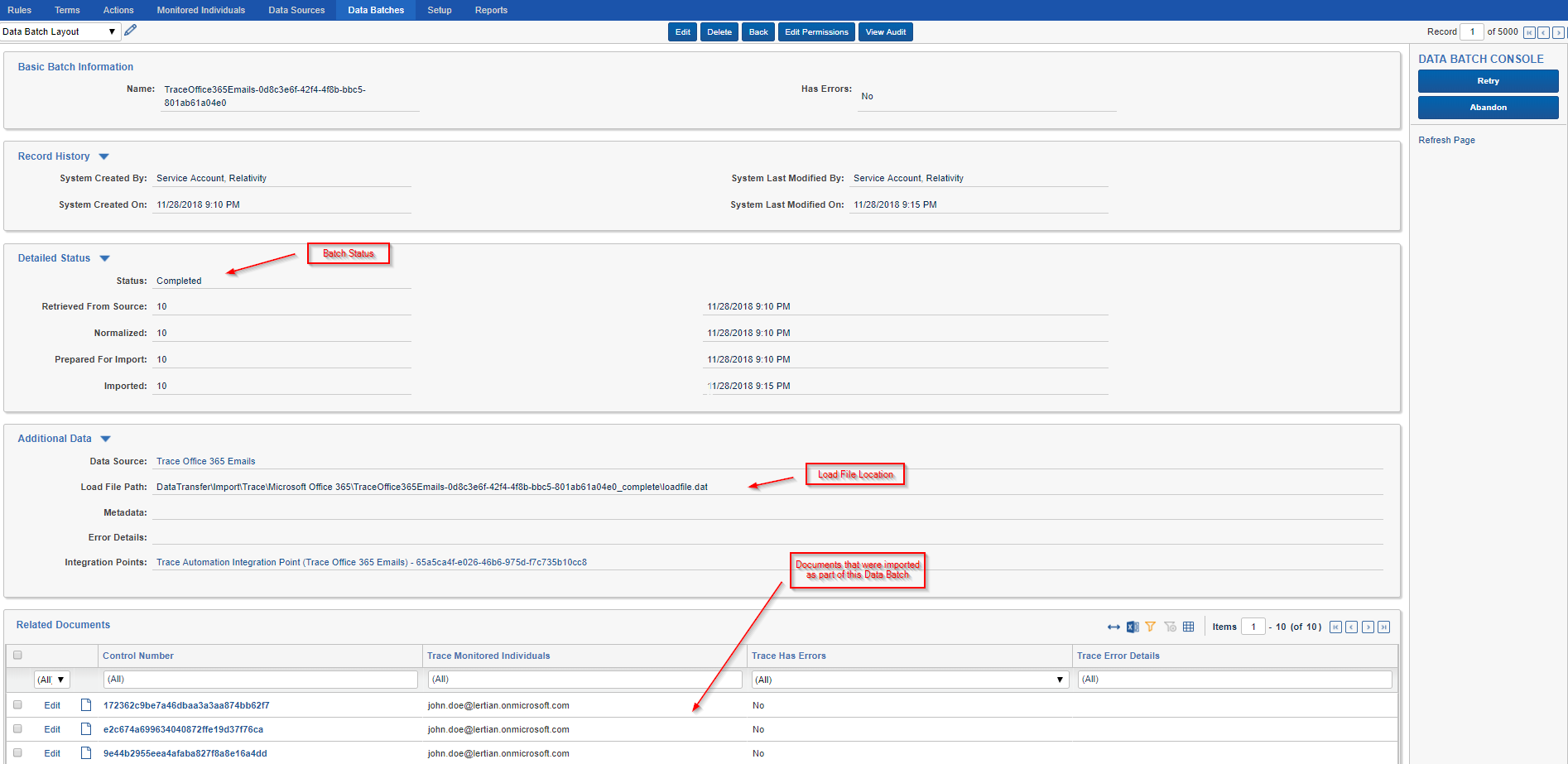
A Data Batch corresponds to a load file on disk that needs to be imported with specific settings and field mappings. It is a central tracking object for how the data was generated, normalized and aggregated into a load file. It provides status of the overall import process and allows for a deep audit history trail from native data source to Relativity.
Once a batch begins the Ingestion process (when status is set to: ReadyForImport), the Ingestion task will create an integration point from the Data Source’s configured Ingestion Profile (this information includes import settings and data mappings).
Trace will only create Integration Points in each workspace up to the number specified in the Max Simultaneous Import Jobs setting on the Ingestion Task (default 25). Once that number of Integration Point jobs are created, additional data batches will stay in the ReadyForImport status and no additional Integration Point jobs will be created until enough jobs finish to bring the total back under the specified maximum.
Data Batch Retry and Error Resolution Workflow
By default, Data Batches that fail will be automatically retried up to 3 times, where the 3 retries are attempted after 1 hour, 3 hours, and 6 hours, respectively. When preparing to retry, the status of the Data Batch is marked as PendingRetry. The retry count and the last time it was retried can be viewed on the layout as well. This automatic retry is a full retry, starting from the RetrievedFromSource status. Data Batches that fail all the configured retries will set Has Errors to true, populate the Error Details field with the details of the specific error encountered, and be given a status of CompletedWithErrors.
If some natives fail due to extraction issues, Trace will automatically split a Data Batch onto two Data Batches: 1st Data Batch - that contains all natives which passed extraction and 2nd Data Batch - that contains failed natives. The second Data Batch will be retried three times and if fails, it would go to CompletedWithError status. This logic is to ensure that Trace will try ingesting as much data as possible and isolate failed data in a separate Data Batch.
If a Data Batch completes successfully but has errors at the document level (for example, if a date field value could not be parsed as a date), the Data Batch will be marked CompletedWithDocumentLevelErrors and there will not be an automatic retry.
Data Batch objects have associated Mass Operations (and corresponding Data Batch console UI buttons) to help with state resolution
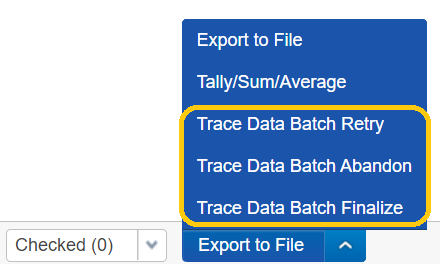
-
Trace Data Batch Retry– submits the Data Batch to be retried by Trace. This is a full retry that reverts the Data Batch to theRetrievedFromSourcestatus and Trace will once again attempt to ingest the data.If it is not enabled on the Data Source you will need to perform a
Trace Data Batch Retryon all documents in that data batch. -
Trace Data Batch Abandon– updates the Data Batch to indicate that it has been manually resolved and that no further work needs to be done. Using this action is necessary when errors are resolved manually because otherwise the Ingestion task will continue to report the presence of Data Batches in the CompletedWithErrors status.
If a Data Batch sits in a status other than Completed, CompletedWithErrors, CompletedWithDocumentLevelErrors, or Abandoned for longer than 24 hours (timeout configurable with the Data Batch Timeout In Hours setting on the Data Validation Task), it will automatically be: (1) Retried if automatic retry is configured for workspace and retry attempts exist for the stuck data batch (Data Batches can hang in the Enriching status and this reduces the number of Data Batches that must be retried manually). (2) Marked CompletedWithErrors if the Data Batch exhausted its retry attempts and the error was unable to be resolved. (3) Marked Abandoned if the Data Batch does not have any files. This functionality helps ensure that temporary system issues do not lead to Data Batches being stuck indefinitely containing documents that never make it into the workspace.