Analytics
Analytics capabilities consist of language identification, name normalization, email threading, textual near duplicate identification, repeated content identification, find conceptually similar content, and topic clustering.
Analytics Automation
Conceptual Analytics Indexes, Classification Analytics Indexes, and Structured Analytics Sets can all be automated with Relativity Trace.
The Analytics application must be installed into the workspace before analytics automation can be used.
Conceptual and Classification Analytics
Relativity Trace will create the Trace Conceptual Analytics Index and the Trace Classification Analytics Index after install or upgrade of the Trace application if the Analytics application is installed in the workspace. By default, these indexes will not build automatically. To begin automation of an index, first perform a Full Build manually through the Relativity UI. Subsequently, Relativity Trace will automate incremental builds of the index based on the value of the Global Analytics Build Frequency In Minutes setting defined on the Indexing Task. To disable automatic builds of the Trace Conceptual and Classification indexes, set the value of the Global Analytics Build Frequency In Minutes setting to -1.
Structured Analytics
Email Threading
It is suggested to use the AI Extracted Text Cleansing Data Transform and the “Duplicative Content - Remove Already Ingested Email segments” setting to ignore duplicative email segments rather than Email Threading in Structured Analytics sets as finding inclusive emails is less effective due to the growing of email threads each day with ongoing monitoring.
Email Threading identifies “inclusive emails” that contain all prior content within a thread to reduce the number of documents that need to be reviewed. More information can be found here.
Name Normalization
Name Normalization groups different email address aliases to the same individual (entity) to improve the understanding of who is communicating. Name Normalization is necessary to use the Communication Analysis widget on the document page to analyze social networks. More information can be found here.
Textual Near Duplicate Identification
Textual Near Duplicate Identification locates similar communications or attachments for removal. More information can be found here.
Setting Textually Similar to 100% would only remove exact textual duplicate.
Language Identification
It is suggested to use the Language Identification Data Transformation rather than the Language Identification in Structured Analytics sets to produce Language Identification results prior to the creation of a Document.
Language Identification detects the primary language and other languages used within a communication. More information can be found here.
Repeated Content Identification
Repeated Content Identification will identify section of communications that are repeated through a high number of communications such as disclaimers or common language. Once identified, this irrelevant repetitive content can be removed using Replace Data Transformations.
Configuring the Automation of Structured Analytics Sets
Relativity Trace can trigger automatic builds of any Structured Analytics Set defined in the workspace. It is possible to configure automation of multiple Structured Analytics Sets at the same time with different settings for build frequency, population scope and analysis scope.
-
Create the Structured Analytics Set(s) that will be automated and run Full Builds on them.
For recommendations on how to configure each of the different types of Structured Analytics Sets including Saved Search details, how frequently to run, and what kind of builds to automate, please contact support@relativity.com
-
Edit the Indexing Task from the Setup page. Under Task Settings, the
Sas Automation Configuration Jsonfield should automatically populate with a JSON node for every Structured Analytics Set defined in the workspace: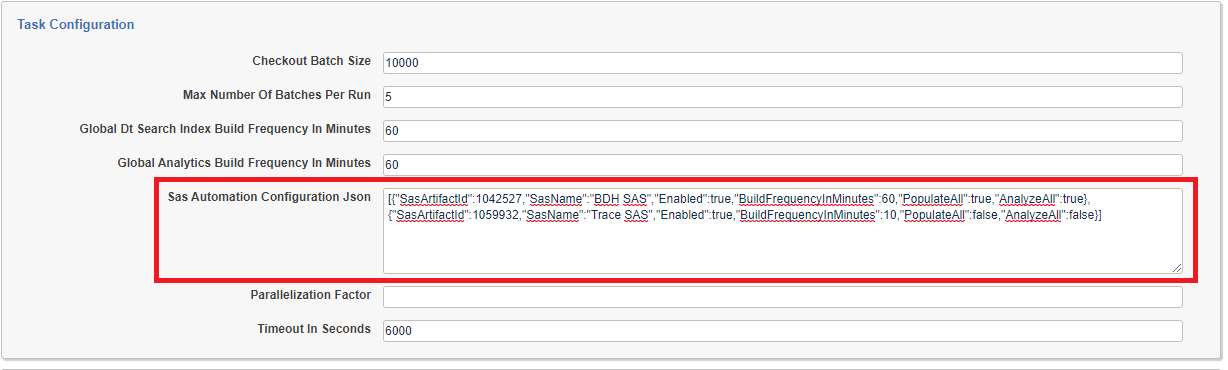
-
For each Structured Analytics Set that should be automated, perform the following steps:
-
Find the Structured Analytics Set by looking for its name in the
SasNamefield -
In the same JSON node (wrapped with {}), change the
Enabledproperty totrue -
Change the
BuildFrequencyInMinutesproperty to the appropriate build frequency in minutesThis is the most frequently the Structured Analytics Set will be built, if a build takes longer than the interval then the next build will start when the previous one ends. Be careful not to build more frequently than needed as every build consumes resources on the Analytics server.
-
Change the
PopulateAllproperty totrueif the underlying index should be repopulated with all relevant documents before each build (truefor a full build,falsefor an incremental build)Setting
PopulateAlltotruecan cause builds to take much longer and consume a lot more resources on the Analytics server. -
Change the
AnalyzeAllproperty totrueif the entire index should be analyzed in each build (truefor a full build,falsefor an incremental build)Setting
AnalyzeAlltotruecan cause builds to take much longer and consume a lot more resources on the Analytics server.
-
-
Click Save and the Trace Manager Agent will automate for every Structured Analytics set with Enabled = true.