Extensible API’s
Relativity Trace is an extensible platform that supports open API’s to augment standard functionality.
Table of contents
- Overview
- Ingest Data From Custom Data Sources
- Workflow Recommendations
- Ingest Monitored Individuals Information
Overview
Relativity Trace API is based and fully dependent on Relativity Dynamic Objects (RDOs). Relativity Trace does not have any custom APIs outside of RDOs. Please, refer to Relativity API Documentation on specifics on how to interact with RDOs.
This documents provides specifications on how one can interact with RDOs specific to Trace.
There are two key ingredients that Trace needs in order to work:
- Actual Data from a Data Source
- Information about Monitored Individuals
This documents provides information on how to build custom integration for both use cases.
Ingest Data From Custom Data Sources
The Trace Proactive Ingestion system (that powers Trace) allows Administrators and Data Sources to automatically and continuously ingest data into Relativity. The framework is built on top of Relativity Integration Points.
The key benefits of the Proactive Ingestion Framework include:
-
Reconciliation from Data Source through Transcription/Normalization to Relativity
-
Data can be autonomously and continuously ingested
-
Data can be pushed from a 3rd party data processor in a generic format (instead of pulled from Relativity with custom connectors)
-
Data is broken into batches improving stability and throughput
-
Data can be manually previewed to facilitate field mapping troubleshooting
-
Data can be re-imported into Relativity at any point (asynchronously from retrieval from the Data Source)
-
Performance monitoring of entire data ingestion pipeline (bottleneck identification, SLA metrics, proactive alerting)
It is designed to work with Load Files as an intermediate step between Source and Relativity ingestion. Consumer of the TPI needs to produce a Load File and make an REST call to Relativity telling it the location of the Load File along with other ingestion configurations. After that, Trace will take the Load File and automatically import it using the provided configurations.
Glossary
-
Data Batch: RDO that contains all needed information about Load File and its ingestion status
-
Load File: Delimited data file on disk, usually CSV or DAT but can be anything with proper delimiters
-
Integration Point: System that executes data ingestion into Relativity, operated by Trace. Trace creates one integration point per Data Batch and monitors its status along with any retries and validation
-
Data Source: Any external system that works with Trace API. It is responsible for generating Load Files and creation of Data Batches
-
Data Source Type: Defines inputs to a particular data source. Data Source Type can be mapped to multiple Data Sources
-
TPI: Trace Proactive Ingestion
Prerequisites: Load File and Ingestion Profile
-
Install “Trace” application
-
Install “Integration Points” application
-
Create Ingestion Profile and adjust advanced settings (encoding, native file path field, etc;)
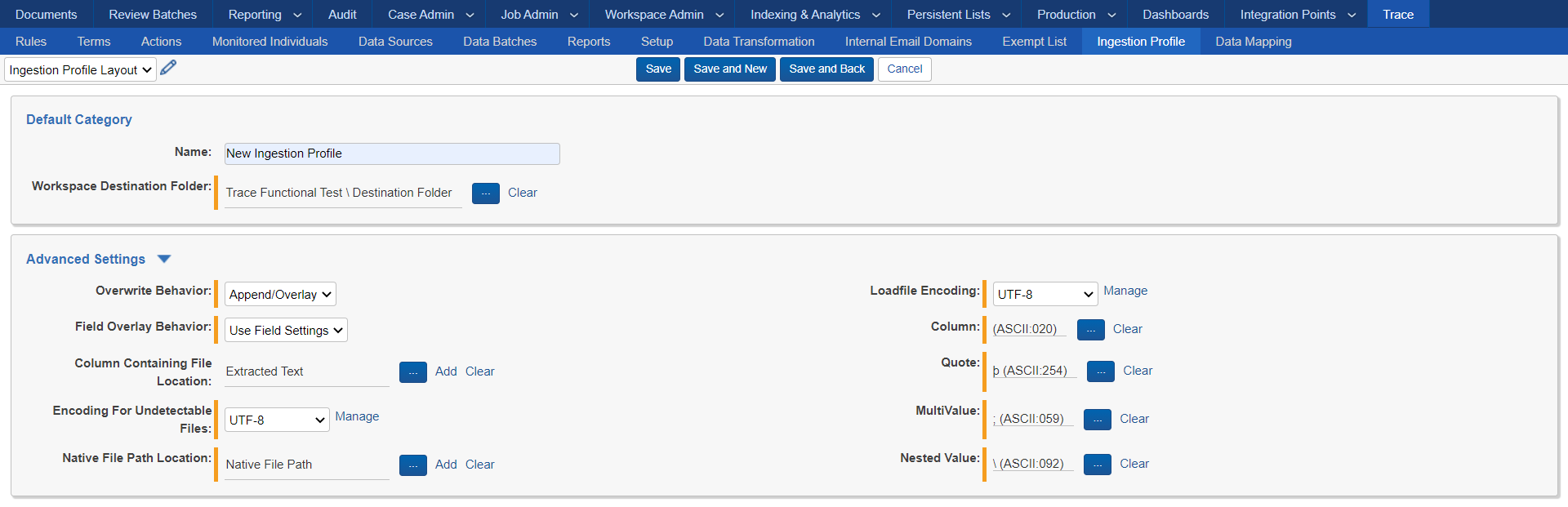
-
Save Ingestion Profile
-
Link/Create Data Mappings

Source Field Identifier: Name of the column in the loadfile
Relativity Field: The field to which the value in the loadfile will be written
Type: The data mapping type. See User Documentation
Data Batch Overview
Data Batch is a unit of work in TPI, it has all the needed configuration and status information to ingest data and monitor ingestion progress.
The below screenshot shows a sample Data Batch RDO in Relativity:
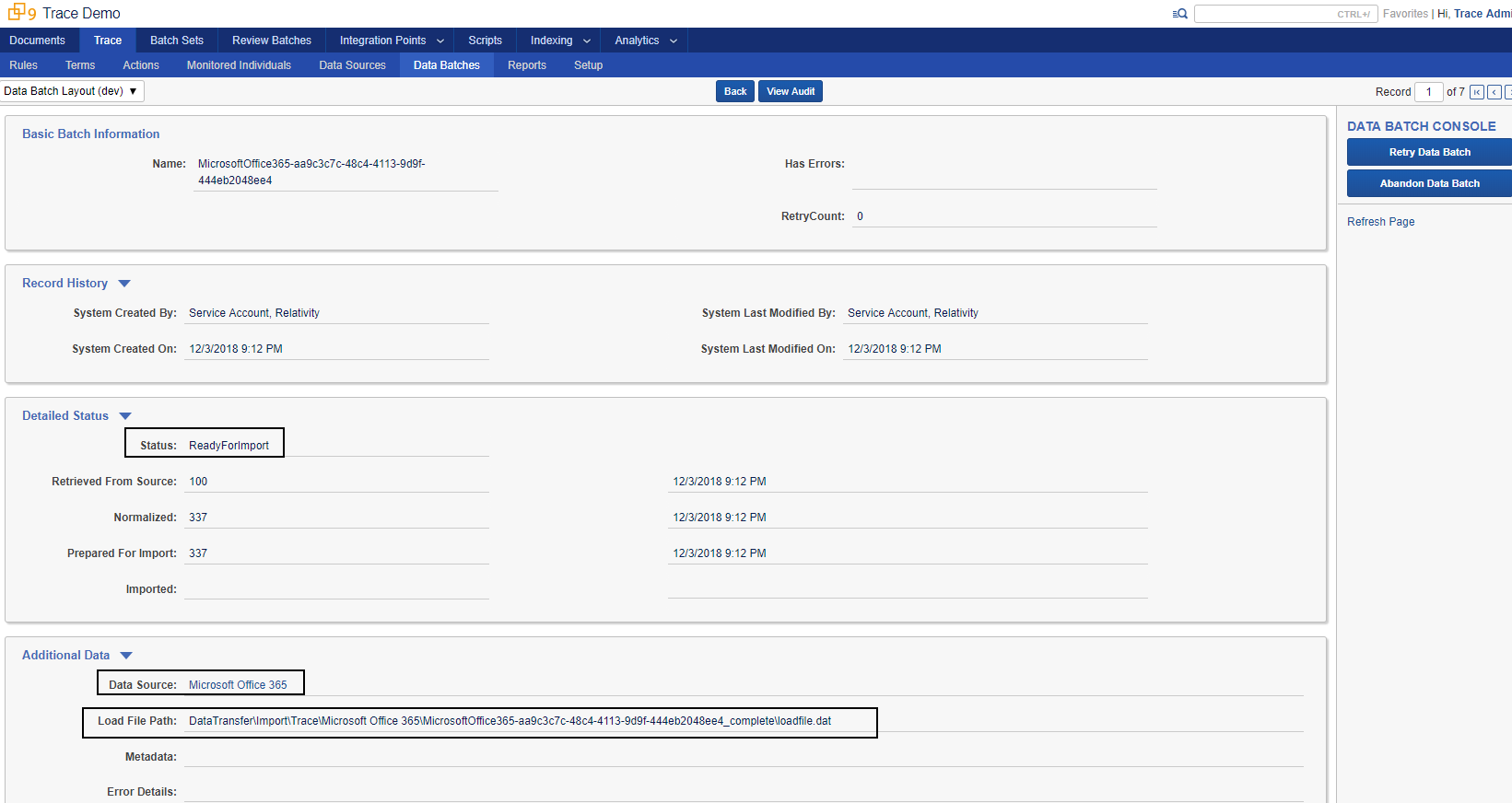
When a Data Source creates a Data Batch, several fields must be filled out:
-
Status
ReadyForImportsignals Trace to start ingesting the data-
All needed configuration is written on the Data Batch
-
Load File has been successfully copied to Relativity Fileshare
-
-
Created,RetrievedFromSourceandNormalizedcan be used to track data flow in Relativity for reconciliation purposes by the Data Source -
Importing,Completed,CompletedWithErrors, andCompletedWithDocumentLevelErrorsstatuses are populated by Trace automatically for ingestion tracking purposes - For each Status, Data Source can specify document count and time stamp (optional)

-
Data Source
- Specify Data Source of the Data Batch
- Load File Path
- Specify path to the relativity location of the load file
- Specify path to the relativity location of the load file
- Specify Data Source of the Data Batch

Ingestion API Usage
Working with TPI involves several steps in a base workflow:
-
Create Load File with data in a Fileshare accessible by Relativity
-
Create Data Batch RDO in Relativity
-
Status set to
ReadyforImport -
Data Source Selected to Office 365 Email
-
Load File Path filled
DataTransfer\Import\Office365Emails\20180511200815UTC-20180511210839UTC\loadfile.dat
-
On next Ingestion task check-in Trace will automatically ingest the data by creating an Integration Point and will validate the import was successful.
Data Batch creation (Quick Start)
Since Data Batch is an RDO, standard Relativity API can be used to manage it. Sample below shows how to create Data Batches with Relativity REST (generic API). One can prototype with Relativity REST without having to write any code. We recommend tools such as Fiddler to prototype sample calls ahead of creating full solutions in code.
Data Batch Statuses
Below status identifiers are needed to set a Data Batch to a particular stage of processing. The identifiers are the same across all versions of Relativity and Trace application.
-
29D19E38-8096-4A63-9496-F6E02D40FBFF- GUID identifier forCreatedstatus -
5932D23F-697B-4950-AE55-1E38AFDD4D2C- GUID identifier forRetrievedFromSourcestatus -
B4680628-67EE-47F7-813C-51DEA69CB19A- GUID identifier forNormalizedstatus -
32452D3D-35D2-4FF5-92E6-1DD01D755482– GUID identifier forReadyForImportstatus -
68FCCFB2-6CE4-442C-A402-26A76E37A961– GUID identifier forAbandonedstatus
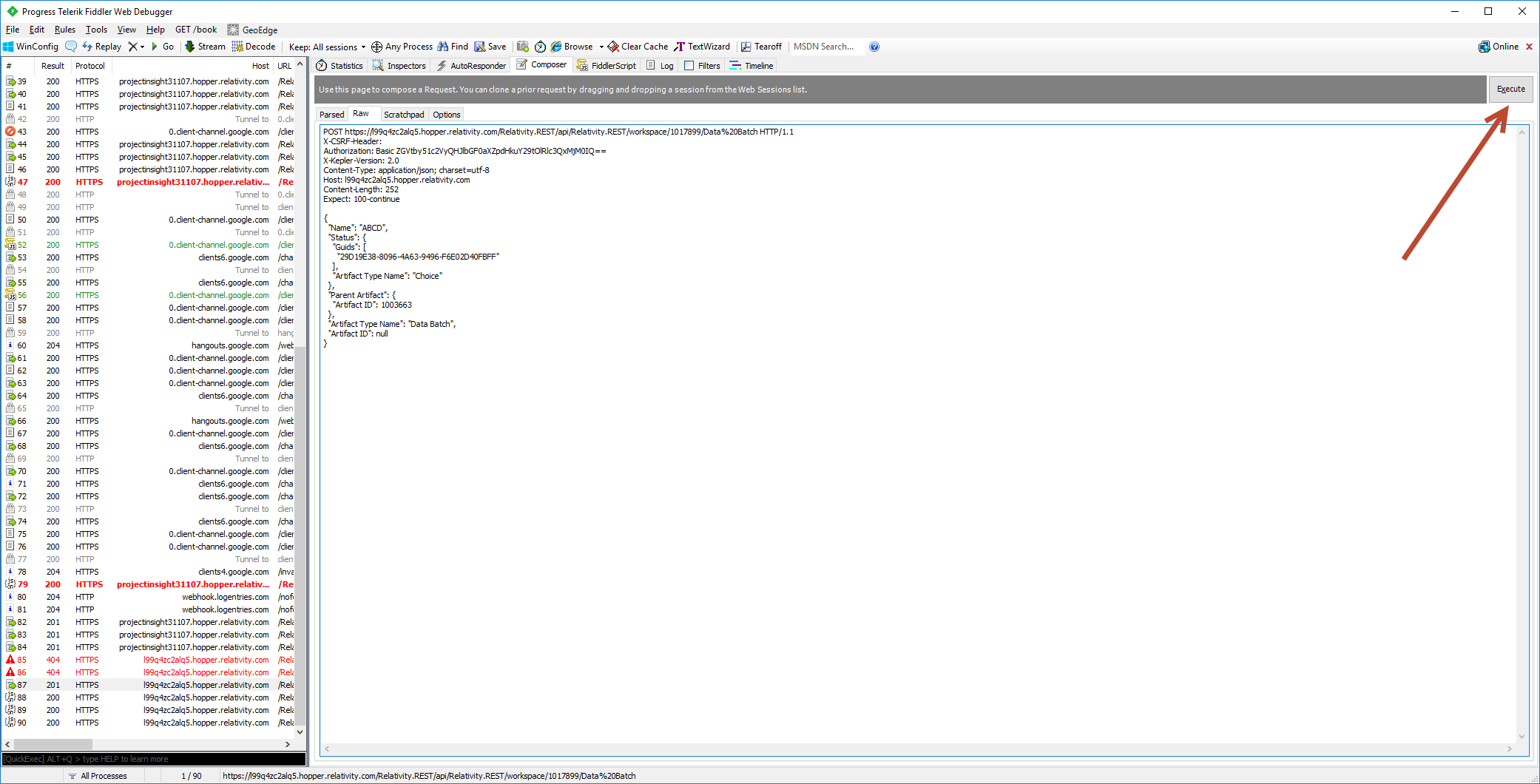
Create Data Batch
Below sample request will create a Data Batch associated with Load File DataTransfer\Import\Office365Email\20180511200815UTC-20180511210839UTC\loadfile.dat
POST https://REPLACE_WITH_RELATIVITY_ROOT/Relativity.REST/api/Relativity.REST/workspace/1017899/Data%20Batch HTTP/1.1
X-CSRF-Header:
Authorization: Basic ZGVtby51c2VyQHJlbGF0aXZpdHkuY29tOmRlbW9Vc2VyUGFzc3dvcmQ=
X-Kepler-Version: 2.0
Content-Type: application/json; charset=utf-8
Host: REPLACE_WITH_RELATIVITY_ROOT
Content-Length: 252
Expect: 100-continue
{
"Name": "Test Data Batch",
"Status": {
"Guids": [
"29D19E38-8096-4A63-9496-F6E02D40FBFF"
],
"Artifact Type Name": "Choice"
},
"Load File Path": "DataTransfer\Import\Office365Email\20180511200815UTC-20180511210839UTC\loadfile.dat",
"Data Source": {
"Artifact ID": 3453563
},
"Parent Artifact": {
"Artifact ID": 1003663
},
"RetryCount": 0,
"Artifact Type Name": "Data Batch"
}
1017899 – workspace ID
ZGVtby51c2VyQHJlbGF0aXZpdHkuY29tOmRlbW9Vc2VyUGFzc3dvcmQ= - base64 encoded username:password format
29D19E38-8096-4A63-9496-F6E02D40FBFF – GUID identifier for Created status
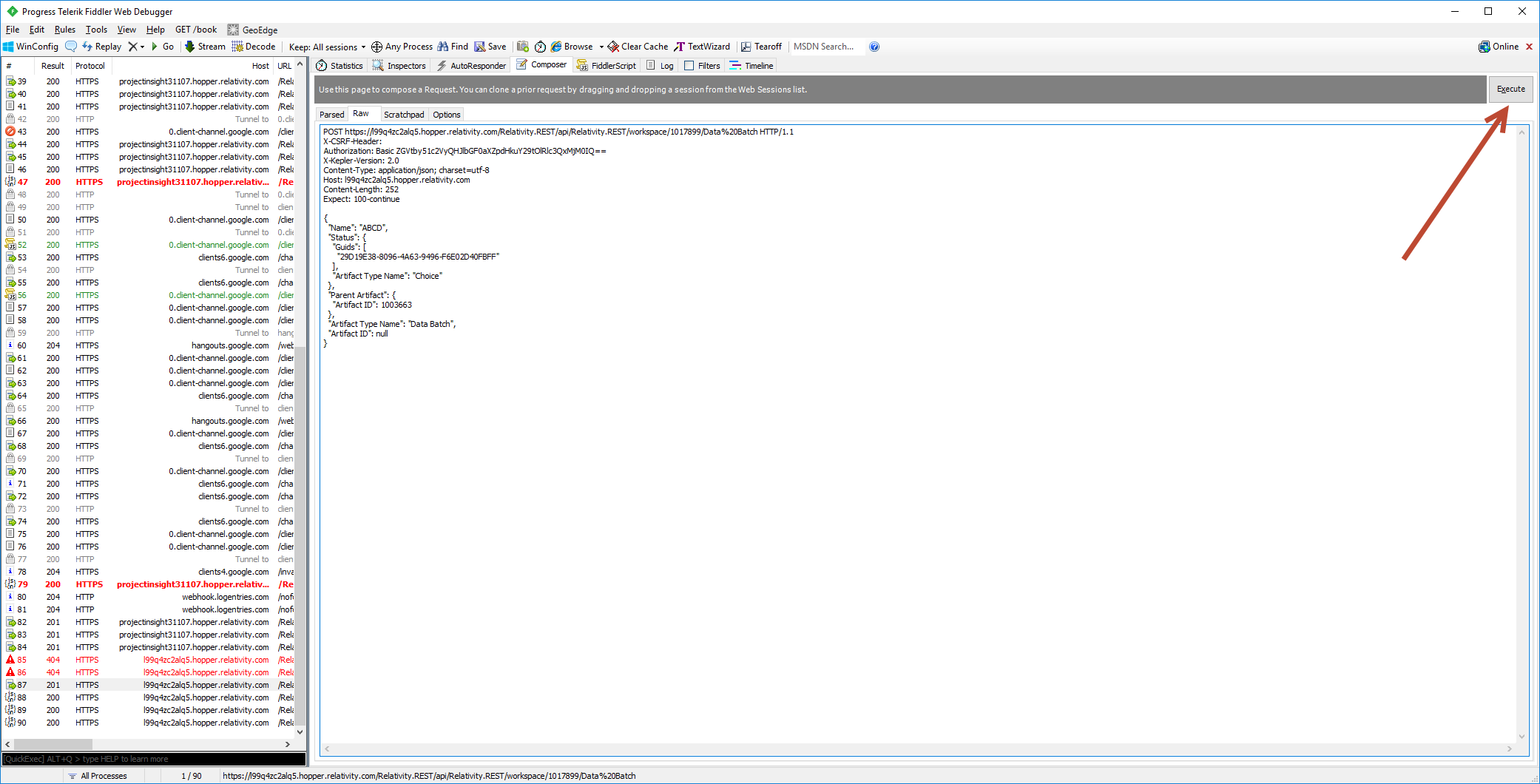
Above request must be executed using Fiddler, for example:
Update Data Batch
Below sample requests will update a Data Batch associated with Load File DataTransfer\Import\Office365Email\20180511200815UTC-20180511210839UTC\loadfile.dat to ReadyForImport status
PUT
https://REPLACE_WITH_RELATIVITY_ROOT/Relativity.REST/api/Relativity.REST/workspace/1017899/Data%20Batch/1017877 HTTP/1.1
X-CSRF-Header:
Authorization: Basic
ZGVtby51c2VyQHJlbGF0aXZpdHkuY29tOmRlbW9Vc2VyUGFzc3dvcmQ=
X-Kepler-Version: 2.0
Content-Type: application/json; charset=utf-8
Host: REPLACE_WITH_RELATIVITY_ROOT
Content-Length: 252
Expect: 100-continue
{
"Status": {
"Guids": [
"32452D3D-35D2-4FF5-92E6-1DD01D755482"
],
"Artifact Type Name": "Choice"
},
"DocumentCount_LoadFileGenerated": "500",
"Timestamp_LoadFileGenerated": "3\/27\/2018 4:15:13 PM",
"Parent Artifact": {
"Artifact ID": 1003663
},
"Artifact Type Name": "Data Batch",
"Artifact ID": 1017877
}
1017899 – Workspace ID
1017877 - Artifact ID of Test Data Batch create in the previous section
ZGVtby51c2VyQHJlbGF0aXZpdHkuY29tOmRlbW9Vc2VyUGFzc3dvcmQ= - base64 encoded username:password
DataTransfer\Import\Office365Email\20180511200815UTC-20180511210839UTC\loadfile.dat - load file location
32452D3D-35D2-4FF5-92E6-1DD01D755482 – GUID identifier for ReadyForImport status
Above request must be executed using Fiddler, for example:
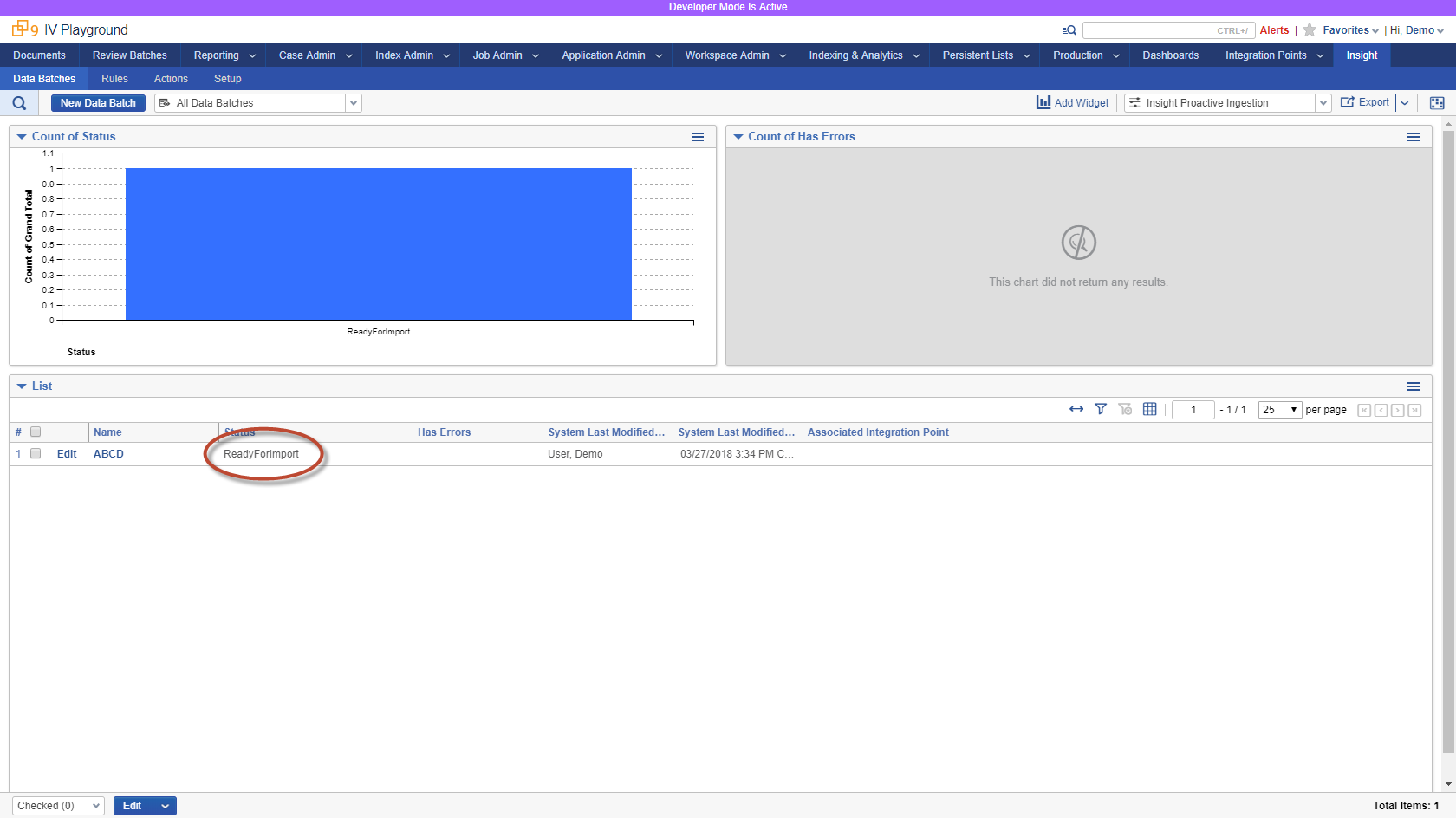
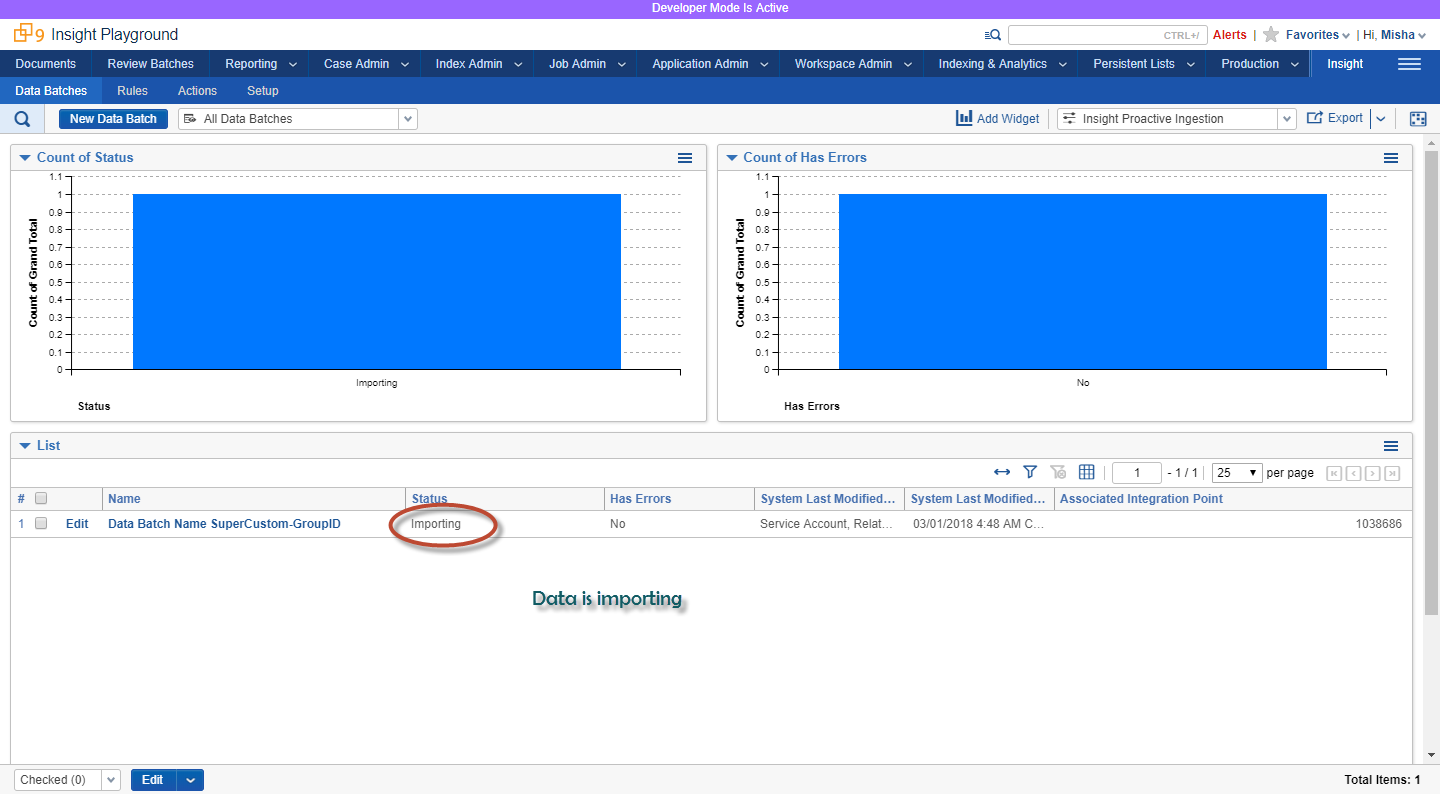
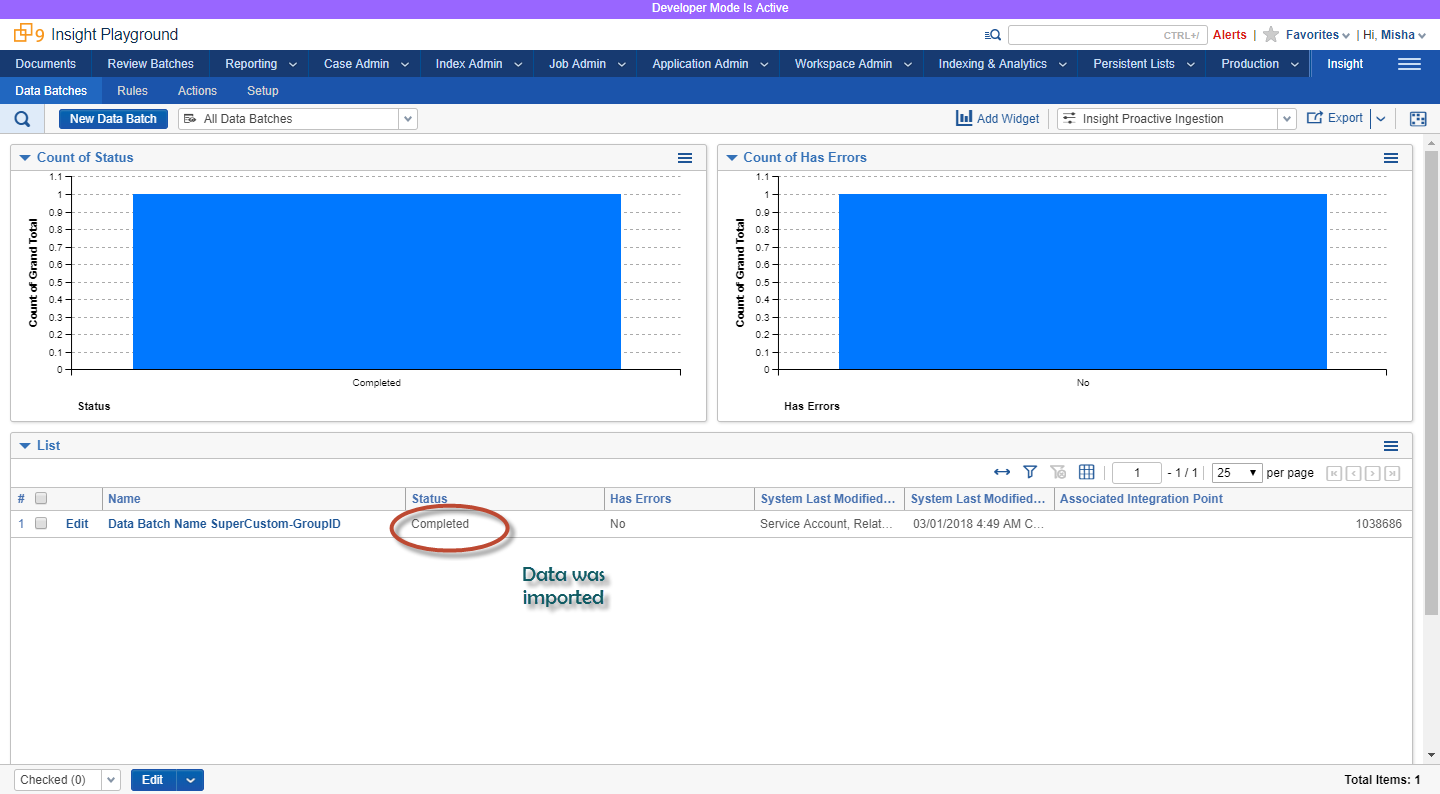
After Data Batch is created or updated, it can be monitored in Relativity UI (or programmatically via identifier returned from Create API request)
Workflow Recommendations
Security
In order to work with TPI in a secure manner, create a new user with limited permissions: enable access only to Relativity objects that are needed: Data Batch, Data Source and particular fields ( Trace Has Errors and Trace Error Details ) on a Document object.
Load File Specifications
Full list of specifications: https://help.relativity.com/9.6/Content/Relativity/Relativity_Desktop_Client/Importing/Load_file_specifications.htm
Recommended approach to generate Load Files (.dat) with the following specs:
| Value | Character | ASCII Number | Notes |
|---|---|---|---|
| Column | 020 | Must replace this character in your data | |
| Quote | þ | 254 | Must replace this character in your data |
| Newline | 013 + 010 | Carriage Return + Line Feed Character | |
| Multi-Value | ; | 059 | |
| Nested Value | \ | 092 |
Text Fields
All text fields in the load file must avoid special characters mentioned above. They are reserved as delimiters and will produce non-ingestible data. Those characters must be explicitly replaced. Recommended approach is to replace Column (ASCII 020) and Quote (ASCII 254) characters with a space. C# sample below illustrates one way to replace special characters:
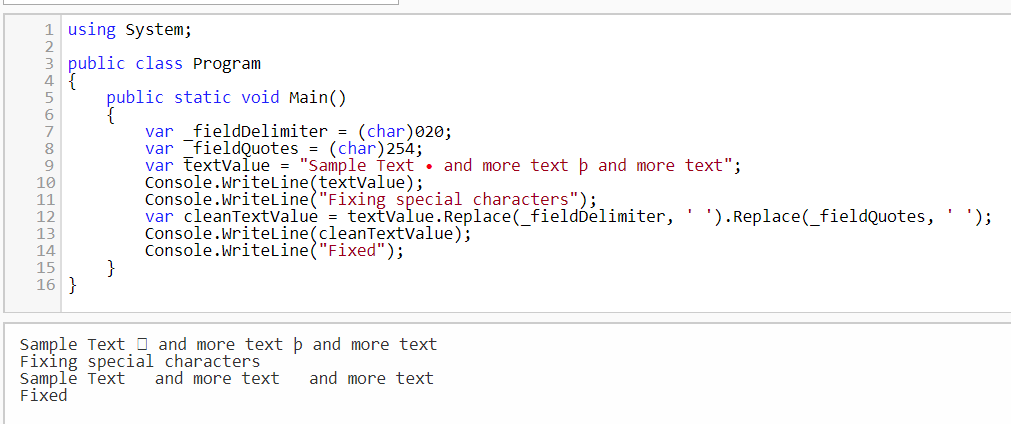
Date Fields
Relativity Trace validates and normalizes all values in columns that are mapped to date fields to a standard format before ingestion. If a date value cannot be parsed, the column will be cleared, the row will be marked Trace Has Errors = true, and the original string value will be placed in the Trace Error Details field. This approach prevents invalid date strings from blocking ingestion of documents into the workspace.
Due to varying minimum and maximum values for dates, Relativity Trace will consider any date with a year less than 1800 or greater than 2200 to be invalid.
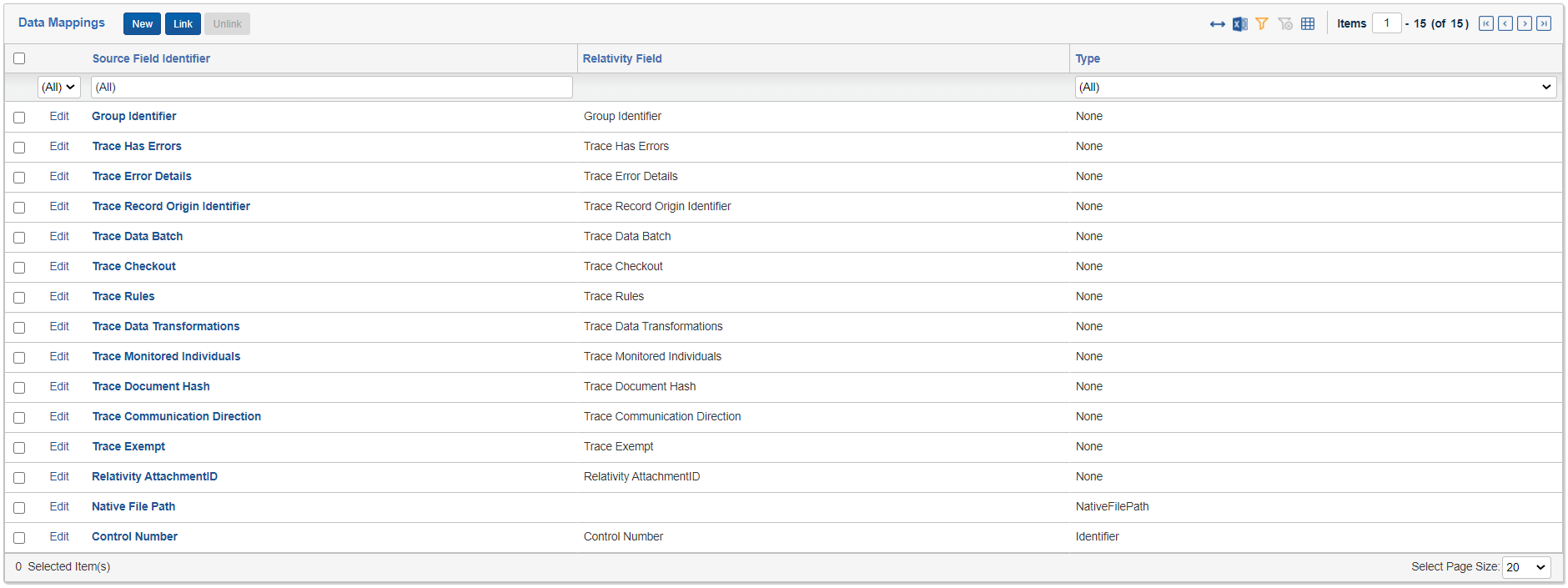
Data Mappings stored on Ingestion Profile
The following fields must be part of the Load File and must be mapped to appropriate Relativity fields via Data Mappings on the Ingestion Profile:
Required (absolute musts)
-
Object Type Identifier - this is usually called
Control Numberbut is whichever field is the identifier for the Document Object in Relativity -
Trace Monitored Individuals– list of monitored people associated with each record -
Trace Document Hash- uniquely identifies a particular record. This will be used by Trace for de-deduplication purposes-
IMPORTANT: column name in the load file must be called
Trace Document Hash
-
-
Trace Has Errors– true/false. True, if particular document has errors (e.g. audio file too big to transcribe, etc;) -
Trace Error Details– details of the individual item’s error (stack trace, retry information, etc;) -
Trace Data Transformations- must be set to empty string. This ensures that any Data Transformations tags are cleared. -
Trace Data Batch- column must exist but value should be empty, will be filled in with the correct Data Batch Identifier in each row before ingestion -
Relativity Attachment ID- must be set to empty string and mapped toRelativity Attachment IDfield in Relativity. This field is needed for RSMF content. -
Group Identifier- cannot be empty. This field is used to group a parent native file and its children (e.g. an email and its attachments). Every parent native file must have a unique value. Extracted children should have the same value as its parent native file. It is suggested that a unique GUID is used for this value, and that it is different from the values used in other columns.-
IMPORTANT: column name in the load file must be called
Group Identifier
-
-
Trace Is Extracted- a yes/no field populated during Data Extraction denoting whether a document is a Native or was Extracted. If value not determined or provided, it will default to No.
Recommended
Trace Data Batch– name of the batchTrace Checkout– must be set to empty string. This ensures Trace can restart indexing and term searching for particular item in case of changes to an existing document (overlay scenario)Trace Rules– must be set to empty string. This ensures that any Rule tags are cleared.Trace Rule Terms– must be set to empty string. This ensures that any Rule Terms tags are cleared.Trace Terms- must be set to empty string. This ensures that any Term tags are cleared.Trace Record Origin Identifier- this should be an id of a record from it’s data origin system. Once included, Trace will track this value across all Trace actions on a particular record. This helps to reconstruct audit trail for a particular record.
Data Batches
Recommended workflow for Data Batch creation ( Created -> RetrievedFromSource -> Normalized -> ReadyForImport ):
-
Create Data Batch with Status
Createdbefore starting data retrieval process -
Update Data Batch status to
RetrievedFromSourcewhen data is retrieved -
If data needs to be enriched or transformed, update Data Batch status to
Normalized -
Once Load File is created, update Data Batch status to
ReadyForImport. Include Import Configuration details. At this point Trace will pick it up and ingest the data into Relativity.
At any stage, you can use Metadata field on the Data Batch to capture information regarding the batch of documents as you go through the process.
Error Handling
-
For item-level errors, always populate the following two fields
Trace Has Errors– true/false. True, if particular document has errors (e.g. audio file too big to transcribe, etc…)
-
Trace Error Details– details of the individual item’s error (stack trace, retry information, etc) -
For batch-level error (e.g. connection failure to retrieve the data, etc…), update status of
Createdbatch toAbandonedand populate batchError Detailswith appropriate error.
Ingest Monitored Individuals Information
You may want to automatically ingest and synchronize Monitored Individuals Information into Trace from your existing system such as Active Directory.
Below diagram shows what is needed in order to synchronize Monitored Individuals information from Active Directory with Trace.

Sample .NET console app code below demonstrates:
- Authentication to Relativity REST API
- Ready / query of Trace-specific RDOs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using Newtonsoft.Json.Linq;
namespace TraceREST
{
public class Program
{
static void Main(string[] args)
{
//Initialize the HttpClient.
HttpClient client = new HttpClient();
client.BaseAddress = new Uri("https://<REPLACEME>.relativity.one");
//Add the Accept header.
client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
//Generate a value for the Authorization header based on a specified
//user name and password.
string authorizationHeaderValue = GenerateBasicAuthorizationParameter("<REPLACEME>", "<REPLACEME>");
//Set the required headers for Relativity.Rest.
client.DefaultRequestHeaders.Add("X-CSRF-Header", string.Empty);
client.DefaultRequestHeaders.Add("Authorization", authorizationHeaderValue);
Console.WriteLine($"Connecting to {client.BaseAddress}...");
//Read the Workspace collection.
string workspaceCollectionString = GetWorkspaceCollectionAsString(client);
List<WorkspaceDto> workspaces = ParseWorkspacesFromWorkspaceCollectionString(workspaceCollectionString);
foreach (var workspace in workspaces)
{
var dataSources = GetTraceDataSourcesForWorkspace(client, workspace.WorkspaceID);
if (dataSources.Any())
{
//Skipping any workspace without data sources
Console.WriteLine(workspace.ToString());
foreach (var dataSourceDto in dataSources)
{
Console.WriteLine($"\t{dataSourceDto}");
}
}
}
Console.ReadLine();
}
static string GenerateBasicAuthorizationParameter(string username, string password)
{
string unencodedUsernameAndPassword = string.Format("{0}:{1}", username, password);
byte[] unencodedBytes = ASCIIEncoding.ASCII.GetBytes(unencodedUsernameAndPassword);
string base64UsernameAndPassword = System.Convert.ToBase64String(unencodedBytes);
return string.Format("Basic {0}", base64UsernameAndPassword);
}
static string GetWorkspaceCollectionAsString(HttpClient client)
{
string url = "Relativity.Rest/Relativity/Workspace";
HttpResponseMessage response = client.GetAsync(url).Result;
if (response.IsSuccessStatusCode)
{
return response.Content.ReadAsStringAsync().Result;
}
Console.WriteLine("The collection GET for Workspace failed.");
return null;
}
static List<WorkspaceDto> ParseWorkspacesFromWorkspaceCollectionString(string workspaceCollection)
{
if (string.IsNullOrEmpty(workspaceCollection))
{
Console.WriteLine("Could not parse Workspace collection string because it was null or empty.");
return null;
}
var workspaces = new List<WorkspaceDto>();
//Turn the workspace collection string into a JObject and obtain the Results JArray.
JObject jWorkspaceResult = JObject.Parse(workspaceCollection);
JArray jWorkspaces = (jWorkspaceResult["Results"] as JArray);
//If the array of Workspaces contained data, attempt to parse the ArtifactID of the first Workspace.
if (jWorkspaces != null && jWorkspaces.Any())
{
foreach (var jWorkspace in jWorkspaces)
{
int? workspaceArtifactId = (int?)jWorkspace["Artifact ID"];
string workspaceName = (string)jWorkspace["Relativity Text Identifier"];
workspaces.Add(new WorkspaceDto()
{
WorkspaceID = workspaceArtifactId ?? 0,
WorkspaceName = workspaceName
});
}
}
return workspaces;
}
private static DataSourceDto GetTraceDataSourceDetails(HttpClient client, int workspaceArtifactID, int dataSourceArtifactID)
{
var dataSourceDetails = new DataSourceDto();
string url = string.Format("Relativity.Rest/Workspace/{0}/Data%20Source/QueryResult?pagesize=1000", workspaceArtifactID);
//TODO: Adjust the fields to only the ones you need, for now get all
string queryPayload = @"{
""condition"":"" 'Artifact ID' > 1000000"",
""fields"":[""*""]
}";
StringContent content = new StringContent(queryPayload);
content.Headers.ContentType = new MediaTypeHeaderValue("application/json");
HttpResponseMessage response = client.PostAsync(url, content).Result;
if (response.IsSuccessStatusCode)
{
//Read the Documents collection, and parse out the Results JArray.
string dataSourcesJSON = response.Content.ReadAsStringAsync().Result;
JObject jDataSourceObjects = JObject.Parse(dataSourcesJSON);
JArray jDataSourceArray = (jDataSourceObjects["Results"] as JArray);
//If the array of Documents contained data, obtain the __Location of the first Document.
if (jDataSourceArray != null && jDataSourceArray.Any())
{
foreach (var jDataSource in jDataSourceArray)
{
string dataSourceName = (string)jDataSource["Relativity Text Identifier"];
bool dataSourceEnabled = (bool)jDataSource["Enabled"];
List<MonitoredIndividualDto> dataSourceMIs = new List<MonitoredIndividualDto>();
//process MonitoredIndividuals
JArray jdataSourceMonitoredIndividuals = (jDataSource["Trace Monitored Individuals"] as JArray);
if (jdataSourceMonitoredIndividuals != null && jdataSourceMonitoredIndividuals.Any())
{
foreach (var jMI in jdataSourceMonitoredIndividuals)
{
int? miArtifactID = (int?)jMI["Artifact ID"];
string miName = (string)jMI["Relativity Text Identifier"];
dataSourceMIs.Add(new MonitoredIndividualDto()
{
MonitoredIndividualArtifactID = miArtifactID ?? 0,
MonitoredIndividualName = miName
});
}
}
dataSourceDetails = new DataSourceDto()
{
WorkspceID = workspaceArtifactID,
DataSourceID = dataSourceArtifactID,
DataSourceName = dataSourceName,
Enabled = dataSourceEnabled,
MonitoredIndividuals = dataSourceMIs
};
}
}
}
else
{
Console.WriteLine($"\t Could not get data source details for ({dataSourceArtifactID})");
}
return dataSourceDetails;
}
private static List<DataSourceDto> GetTraceDataSourcesForWorkspace(HttpClient client, int workspaceArtifactID)
{
var dataSourceDtos = new List<DataSourceDto>();
string url = string.Format("Relativity.Rest/Workspace/{0}/Data%20Source", workspaceArtifactID);
HttpResponseMessage response = client.GetAsync(url).Result;
if (response.IsSuccessStatusCode)
{
//Read the Documents collection, and parse out the Results JArray.
string dataSourcesJSON = response.Content.ReadAsStringAsync().Result;
JObject jDataSourceObjects = JObject.Parse(dataSourcesJSON);
JArray jDataSourceArray = (jDataSourceObjects["Results"] as JArray);
//If the array of Documents contained data, obtain the __Location of the first Document.
if (jDataSourceArray != null && jDataSourceArray.Any())
{
foreach (var jDataSource in jDataSourceArray)
{
int? dataSourceArtifactID = (int?)jDataSource["Artifact ID"];
var dataSourceDetails = GetTraceDataSourceDetails(client, workspaceArtifactID, dataSourceArtifactID ?? 0);
dataSourceDtos.Add(dataSourceDetails);
}
}
}
else
{
Console.WriteLine($"\tNo Trace Data Sources found for workspace {workspaceArtifactID}");
}
return dataSourceDtos;
}
}
#region DTOs
public class DataSourceDto
{
public int WorkspceID { get; set; }
public int DataSourceID { get; set; }
public string DataSourceName { get; set; }
public bool Enabled { get; set; }
public List<MonitoredIndividualDto> MonitoredIndividuals { get; set; }
public override string ToString()
{
return $"Data Source: {DataSourceName}({DataSourceID})\n\tEnabled:{Enabled}\n\tMonitored Individuals Count:{MonitoredIndividuals.Count}";
}
}
public class MonitoredIndividualDto
{
public int MonitoredIndividualArtifactID { get; set; }
public string MonitoredIndividualName { get; set; }
}
public class WorkspaceDto
{
public int WorkspaceID { get; set; }
public string WorkspaceName { get; set; }
public override string ToString()
{
return $"Workspce Name: {WorkspaceName}({WorkspaceID})";
}
}
#endregion
}